
While running the (parametrized) data integration code on different customers/environments, you need to carefully keep track of which kettle.properties file you are using. The environment configurator solves that problem .
About kettle variables
The kettle.properties file is well know to all kettle-developers. For those of you who don't fit into that category (and for some strange reason still read this post): the file contains all environment variables that you want to use in jobs/transformations you execute through either spoon or kitchen. The file sits in your home directory, that is ${HOME}/.kettle and you can add whatever variables you want.
How would you typically use these environment variables? A simple example will illustrate this.
Suppose you use a standard directory for incoming flat file data you need to process. In that case you can create a variable in the kettle.properties file for this directory.
The variable would then be available in all kettle jobs and transformations you will develop. In this case for instance in the Text file input step.

Now if you are running projects for multiple customers, or you are running the same code on different environments (as in development, unit test, acceptance test, production ...) the input directory for your flat files will most likely be different. In order to keep your code generic you would obviously continue to work with the same variable IN_FILE_DIR, but there is only space for 1 kettle.properties file on your system.
Some might say that you can solve this issue by using named parameters which you can pass from the kitchen command line to your jobs/transformations. However if the amount of variables starts to grow, that becomes quite cumbersome to manage.
Environment configurator
In order to avoid manual switching between kettle.properties files for the above scenarios - as I assume many of you are doing - we implemented a little step which we have called the environment configurator.
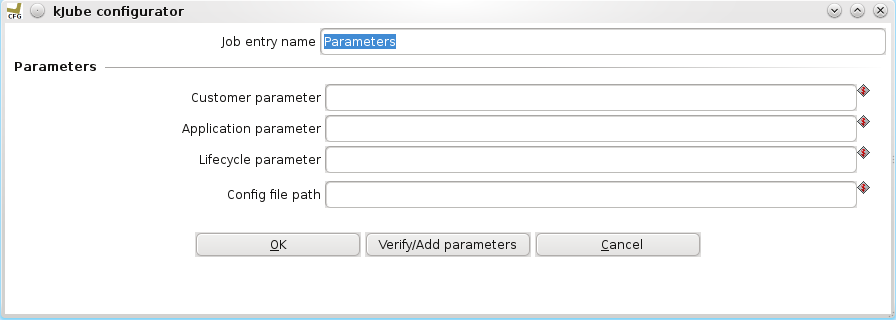
Basically this step will read a kettle.properties file (which you can place in the location of your choice). It will read the .properties file, parse it and set the appropriate environment variables. Any values that are located in your $HOME/.kettle/kettle.properties will be overwritten.
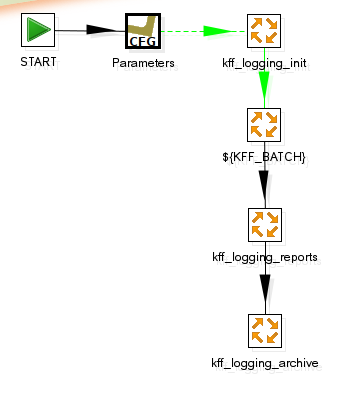
Now if you insert the environment configurator as the first step in your data integration job, as we've done in the KFF-, you can control perfectly which variables will be used to execute your code.
Basically the environment configurator step does expect three input variables which are used throughout the kettle franchising factory, our framework for management and rapid deployment of (multiple) data integration solutions across customers and lifecycles (see more on Google Code about this framework)
Vision
For the moment we've released this kettle plugin as a quick hack for our own projects, to simplify our multi-customer/multi-environment set-up. However a lot of improvements and extension are imaginable. We would love to get the discussion going.
Some food for thought:
Get it
You can get your copy of the environment configurator on Google Code, in the downloads section. All feedback is appreciated. We are very curious to see which use cases you will find for this plug-in.
About kettle variables
The kettle.properties file is well know to all kettle-developers. For those of you who don't fit into that category (and for some strange reason still read this post): the file contains all environment variables that you want to use in jobs/transformations you execute through either spoon or kitchen. The file sits in your home directory, that is ${HOME}/.kettle and you can add whatever variables you want.
How would you typically use these environment variables? A simple example will illustrate this.
Suppose you use a standard directory for incoming flat file data you need to process. In that case you can create a variable in the kettle.properties file for this directory.
IN_FILE_DIR=/kff/projects/my_customer/my_application/data/in/

Now if you are running projects for multiple customers, or you are running the same code on different environments (as in development, unit test, acceptance test, production ...) the input directory for your flat files will most likely be different. In order to keep your code generic you would obviously continue to work with the same variable IN_FILE_DIR, but there is only space for 1 kettle.properties file on your system.
Some might say that you can solve this issue by using named parameters which you can pass from the kitchen command line to your jobs/transformations. However if the amount of variables starts to grow, that becomes quite cumbersome to manage.
Environment configurator
In order to avoid manual switching between kettle.properties files for the above scenarios - as I assume many of you are doing - we implemented a little step which we have called the environment configurator.

Basically this step will read a kettle.properties file (which you can place in the location of your choice). It will read the .properties file, parse it and set the appropriate environment variables. Any values that are located in your $HOME/.kettle/kettle.properties will be overwritten.
Now if you insert the environment configurator as the first step in your data integration job, as we've done in the KFF-, you can control perfectly which variables will be used to execute your code.

Basically the environment configurator step does expect three input variables which are used throughout the kettle franchising factory, our framework for management and rapid deployment of (multiple) data integration solutions across customers and lifecycles (see more on Google Code about this framework)
KFF_CUSTOMER The customer for which you are runingor you can specify the path to your kettle.properties file. (Full details in the documentation.)
KFF_APPLICATION The application code you are running
KFF_LIFECYCLE The environment (DEV, TST, UAT, PRD) you are runnnig
Vision
For the moment we've released this kettle plugin as a quick hack for our own projects, to simplify our multi-customer/multi-environment set-up. However a lot of improvements and extension are imaginable. We would love to get the discussion going.
Some food for thought:
- How many environments do you need? And what naming conventions could we use? Out of the top of my head I can think of the following, but we've only "implemented" the first 4.
- DEV: development
- TST: unit test
- UAI: user acceptance and integration test
- PRD: production
- DRP: mirror of production for performance testing
- ...
- Shouldn't kettle slowly evolve in such a way that the kettle.properties file becomes part of your project code? Or maybe two levels or kettle.properties could exist, the original kettle.properties that contains variables for all your projects, and a project specific one that contains project specific variables.
- If variables become project specific, wouldn't it make sense to be able to edit them inside kettle in a grid that shows the different lifecycle environments and value you are using in each environment. As illustrated below:
Variable
|
DEV
|
TST
|
UAI
|
PRD
|
IN_FILE_DIR
|
/DEV/data/in/
|
/TST/data/in/
|
/UAI/data/in/
|
/PRD/data/in/
|
DWH_SERVER
|
localhost
|
localhost
|
DWH_UAI
|
DWH_PRD
|
DWH_DATABASE
|
MySQL_DWH_DEV
|
MySQL_DWH_TST
|
MySQL_DWH
|
MySQL_DWH
|
...
|
You can get your copy of the environment configurator on Google Code, in the downloads section. All feedback is appreciated. We are very curious to see which use cases you will find for this plug-in.