
Unfortunately I wasn't able to blog my own presentation live during the Pentaho Community Gathering in Cascais, Portugal (PCG10), last saturday. The Live Blog page drew a lot of attention, during and after the event - statistics will follow - and I even got a few times the question whether I would still write a summary of the KFF presentation to go with the slides. Well, I will do no such thing! Instead however ...
Since the whole objective of our presentation was to somehow "launch" KFF - except for a handfull of insiders, no one within the Pentaho Community heard about KFF before - I taught it would be worthwile to write a full walk-through of the presentation for all the persons that might visit the 'PCG10 Live Blog'. So here it goes, no summary, but the full presentation in blog format, plus some little extra's at the end. Enjoy.
KFF, as presented at the Pentaho Community Gathering 2010

As the title slide of my presentation suggests, KFF is all about Pentaho Data Integration, often better known as kettle. KFF has ambitions to be an exciting addition to the existing toolset kettle, spoon, kitchen (all clearly visible in the picture) and at the same time be a stimulator for improvement of these tools.
Why oh why?
Any, and I mean any, consultant that has worked at least once with a data integration tool, be it Informatica, Datastage, MS Integration Services, Business Objects Data Integration, Talend (somehow forgot to name this one at PCG10), Sunopsis - Oracle Warehouse Builder - Oracle Data Integration, has been confronted with the fact that some elementary things are not available out of the box in any of these tools. I think about:
Once we realized this, re-implementing the same concepts again and again became hard to bare.

Luckily Matt and myself had the chance to do a lot of projects together, using kettle, and we started building something we could re-use on our projects back in 2005. With every new project we did with kJube, our 'solution' grew, and we got more and more conviced that we needed to share this.
So in June 2010 we listed out all we had and decided to clean the code and package a first version of what we had to show and share on the Pentaho Community Gathering.

We noticed soon that the first version couldn't include nearly all we had ready. What we present at PCG10, is just a basic version to show you all what were doing. The whole release schedule willt ake until january 2011, if new additions or change requests interfere.
So what is KFF?
We decided to call our solution the Kettle Franchising Factory.
Franchising seemed a nice term because that remained nicely within the existing kettle, spoon, kitchen, chef, carte, etc metaphor. It indicates that the KFF objective is to scale up your data integration restaurant to multiple 'locations' where you cook the same food. That's basically what we want. Make kettle deployments multi environment, multi customer, whilst keeping the set-up standard.
The term Factory refers to the fact that we want every part of the process to go as speedy and automatic as possible. This factory contains all the tools to deploy kettle solutions as swift as possible.

The tools through which we reach those goals are several:
So let's go into details
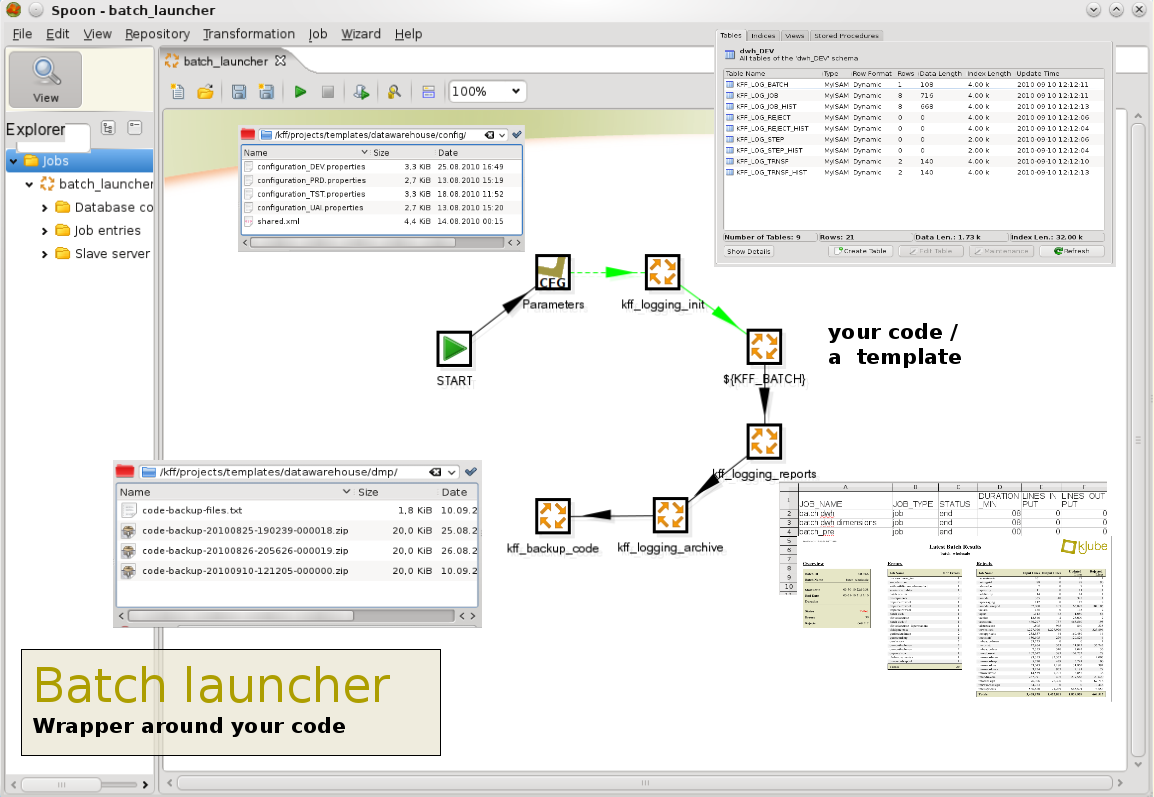
A first element of the KFF we want to show is the 'batch_launcher.kjb'. This kettle job is designed to be a wrapper around your existing ETL code or one of the templates we'll ship with KFF. The objective is make all calls to re-usable logic as logging, archiving etc in this wrapper without the need to modify your code.
What does this job do (as of today):
How does the environment configuration work, and why is it necessary? Well, the fact kettle standard only provides one kettle.properties file in which to put all your parameters is kind of limiting to setting up a multi-environment kettle project. The way you actually switch between environments in a flexible way is actually by changing the content of variables. So we created the environment configurator. I'm not gonna elaborate on this again, since I've blogged about this plug-in in august when we first released it. I believe that blog-post elaborates more than enough on the usage of this step.
Obviously the environment configurator is something that works when you execute code through kitchen, that is in batch mode. However whenever you fire up spoon, it will just read the properties files in your $KETTLE_HOME directory. In order to overcome the problem also in the development interface.
 Consequently, if you have correctly set up your configuration files, the kff_spoon_launcher.sh [No windows script available yet. We do accept contributions from people running Windows as OS.] will automatically set the right configuration files at run time and fire up spoon on the environment you want. As a little addition, nothing more than a little hack, we also change the background of your kettle canvas. That way you see whether you are logged on in DEV, TST, UAI or PRD, which is good to know when you want to launch some code from the kettle interface.
Consequently, if you have correctly set up your configuration files, the kff_spoon_launcher.sh [No windows script available yet. We do accept contributions from people running Windows as OS.] will automatically set the right configuration files at run time and fire up spoon on the environment you want. As a little addition, nothing more than a little hack, we also change the background of your kettle canvas. That way you see whether you are logged on in DEV, TST, UAI or PRD, which is good to know when you want to launch some code from the kettle interface.
So how about that system to create logging tables? Well, the logging tables we use are the standard job, transformation and step logging tables. We tried to stick as much to the existing PDI logging and just add on top of that.
What did we add:
The rejects step isn't the only plug-in we have written over the last few years. The next slide illustrates some other steps that have been developed.
I have blogged about these steps before, so again, I will not write this out again. Also, one step that isn't mentioned here, but which we developed too, and has been contributed back to kettle 4.0 is the data grid step.
Another aspect of KFF are project templates. For the moment, what we have is rather meager - only the datawarehouse template is available -, but we do have quite some stuff in the pipeline that we want to deploy.

So to sum it all up: KFF pretends to be a big box, with all of the below contents.
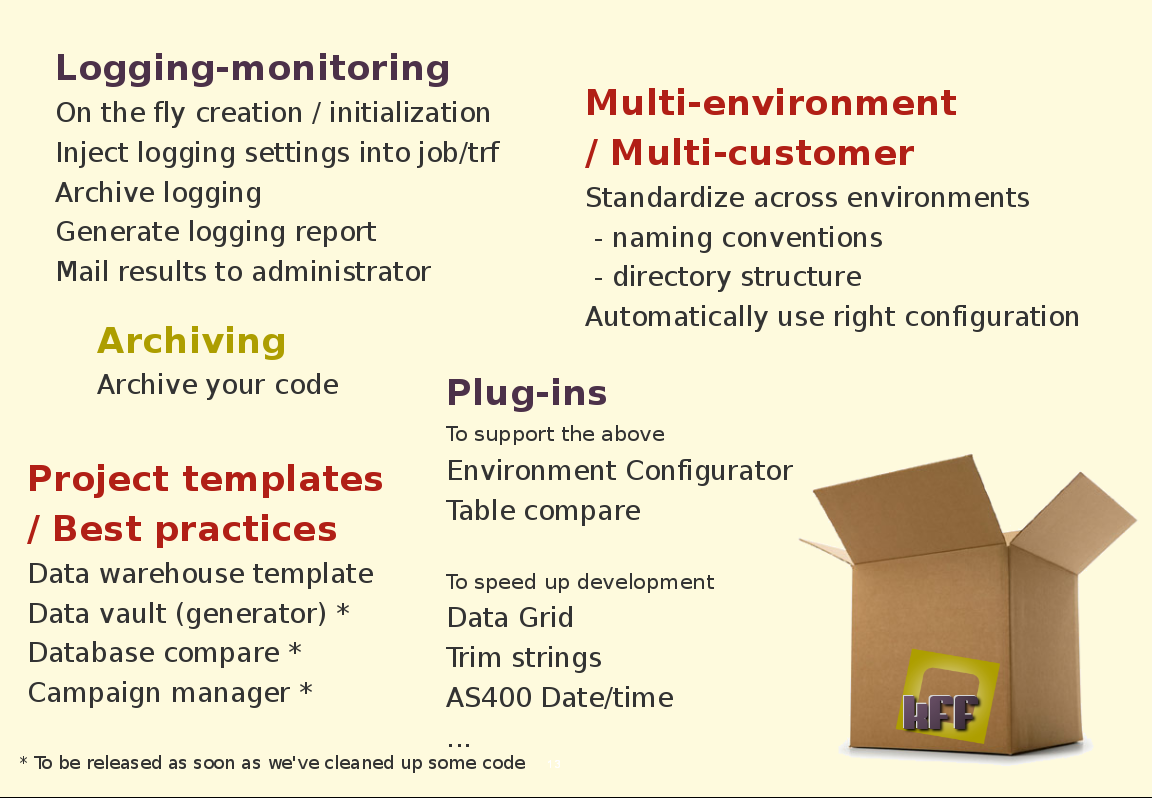
We don't expect all of this to be in there from day one. Actually the day we presented KFF at PCG10 was day 1, so have some patience and let us add what we have over the next months.
How will KFF move forward?
Well we believe the first step was releasing something to the community. We'll keep on doing that. The code for the project is fully open source (GPL) and available no Google Code. Check code.kjube.be or go to the kettle-franchising project on google code. We'll listen to your feedback and adapt where possible!

Also we'll follow these basic guidelines:
Who's in on this?
For the moment, Matt and myself are the drives behind this "project". Older version have been in production with some of kJube's customers for years. Sometimes they contribute, sometimes they are just happy it does what it should.

We hope to welcome a lot of users and contributers over next months.
Feedback
is always welcome!

Thanks!

- A job/transformation logging without set-up or configuration
- Integrated alerting mechanisms (for when things go wrong)
- Integrated reporting
- as part of the alerting or
- just to understand the health of your data integration server
- Guideliness for a multi-environment (DEV, TST, UAI, PRD) set-up
- Easy code versioning and migration between environments
- Automated archiving of your code
- ... etc
Once we realized this, re-implementing the same concepts again and again became hard to bare.

Luckily Matt and myself had the chance to do a lot of projects together, using kettle, and we started building something we could re-use on our projects back in 2005. With every new project we did with kJube, our 'solution' grew, and we got more and more conviced that we needed to share this.
So in June 2010 we listed out all we had and decided to clean the code and package a first version of what we had to show and share on the Pentaho Community Gathering.

We noticed soon that the first version couldn't include nearly all we had ready. What we present at PCG10, is just a basic version to show you all what were doing. The whole release schedule willt ake until january 2011, if new additions or change requests interfere.
So what is KFF?
We decided to call our solution the Kettle Franchising Factory.
Franchising seemed a nice term because that remained nicely within the existing kettle, spoon, kitchen, chef, carte, etc metaphor. It indicates that the KFF objective is to scale up your data integration restaurant to multiple 'locations' where you cook the same food. That's basically what we want. Make kettle deployments multi environment, multi customer, whilst keeping the set-up standard.
The term Factory refers to the fact that we want every part of the process to go as speedy and automatic as possible. This factory contains all the tools to deploy kettle solutions as swift as possible.

The tools through which we reach those goals are several:
- Some of the requirements we meet through proposing set-up standards. We try to make as few things dependend on standards or guideliness, everything should be configurable, but large data integration deployments stay neat and clean only if some clear set-up standards are respected. Also, standards on parametrization need to be imposed if you want to make your code flexible enough to run on multiple environments without further modifications.
- A lot of functionality is implemented using reusable kettle jobs and transformations, often using named variables.
- Quite a few kettle plugins have been written too. We believe that when certain actions can be simplified by providing a kettle plugin, that we should provide that plugin.
- Up to now we have 4 project templates we want to include with the KFF. Some "projects" always have the same structure if one follows best practices, so why should we rewrite things.
- Scripting. Although limited, there is also some scripting involved in KFF.
So let's go into details
A first element of the KFF we want to show is the 'batch_launcher.kjb'. This kettle job is designed to be a wrapper around your existing ETL code or one of the templates we'll ship with KFF. The objective is make all calls to re-usable logic as logging, archiving etc in this wrapper without the need to modify your code.
What does this job do (as of today):
- The first step of this job will read the right configuration file(s) for your current project/environment. For this we've developped a step called the 'environment configurator'. So based upon some input parameters, the environment configurator will override any variables that (might) have been see in kettle.properties to ensure that the right variables are used.
- The job 'kff_logging_init' will
- create logging tables (in case they didn't exist yet), currently on MySQL or Oracle,
- clean up logging tables in case there should be data in there
- check whether the previous run for this project finished (succesfully)
- creates a 'batch run'
- The next job calls one of our project templates currently the datawarehouse template but can easily be replaced by the top level job of your data integration project
- After the data integration code has finished, 'kff_logging_reports' generates standard reports on top of the logging tables . The reports are kept with the kitchen logs.
- 'kff_logging_archive'
- closes the 'batch_run' based on results in the logging tables and
- archives the logging tables (more on that later)
- 'kff_backup_code' makes a zip file of the data integration code which is tagged with the same batch_run_id as the kitchen log file and the generated reports.

How does the environment configuration work, and why is it necessary? Well, the fact kettle standard only provides one kettle.properties file in which to put all your parameters is kind of limiting to setting up a multi-environment kettle project. The way you actually switch between environments in a flexible way is actually by changing the content of variables. So we created the environment configurator. I'm not gonna elaborate on this again, since I've blogged about this plug-in in august when we first released it. I believe that blog-post elaborates more than enough on the usage of this step.
Obviously the environment configurator is something that works when you execute code through kitchen, that is in batch mode. However whenever you fire up spoon, it will just read the properties files in your $KETTLE_HOME directory. In order to overcome the problem also in the development interface.

So how about that system to create logging tables? Well, the logging tables we use are the standard job, transformation and step logging tables. We tried to stick as much to the existing PDI logging and just add on top of that.
What did we add:
- We implemented the concept of a batch logging table. For every time you launch a batch process, in this table a record will be logged that covers your whole batch run. In casu it will log the execution of the top level job. So yes, this is nothing but job logging, but since the top level job has a specific meaning within a batch process, isolating it's logging opens up possibilities.
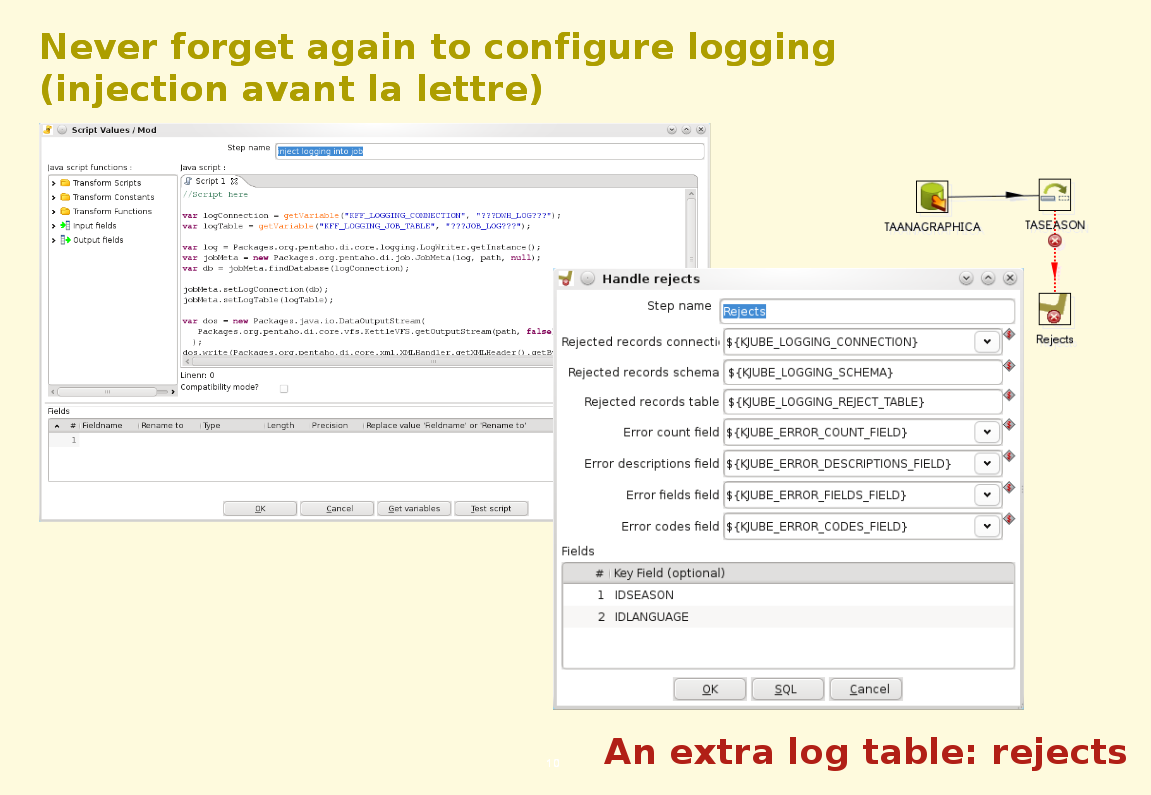
- We also implemented the concept of a rejects logging table. Kettle has great error handling, however one feature we felt was missing is to standardize that error handling. Our reject plug-in merges all records that have been rejected by an output step into a common format and inserts them into our reject logging table. The full records is preserved, so information could theoretically be reprocessed later. [Question Pedro Alvez: "Is the reprocessing part of KFF? Answer: No, since we don't believe automation of that is straight forward enough.]
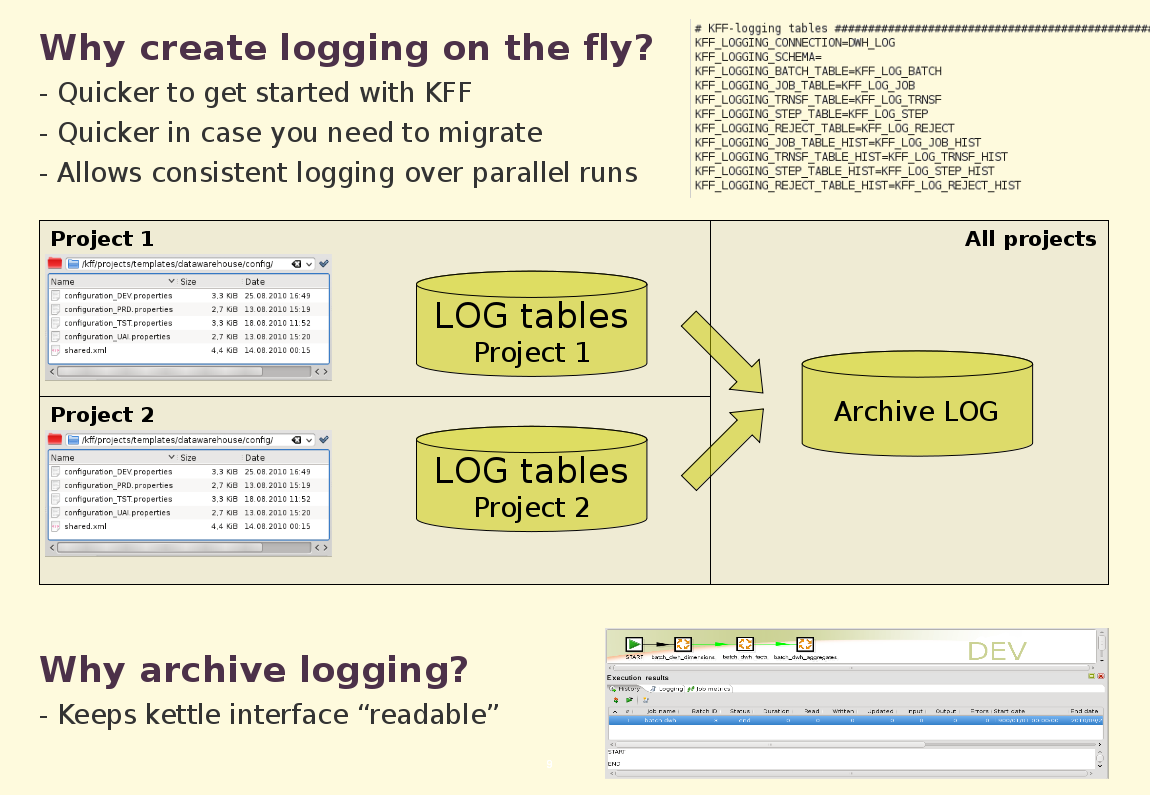
- Logging tables are created on the fly. Why? Well, whenever you are running your jobs/transformations on a new environment you get that nasty errors that your logging tables don't exist. Why should you be bothered with that. If they don't exist, we create them.

- Creating the logging tables on the fly wasn't just done because we like everything to go automatically. Suppose you would want to run two batch processes in parallel. In a set-up with a single set of logging tables your logging information would get mixed up. Not in our set-up. You can simply define a differrent set of logging tables for the second batch run and your logging stays nicely separated.
- Obviously to implement the above, you need to be able to change your logging settings in your jobs and transformations at run-time. For this Matt has written some nifty logging parameters injection code that actually injects the log table information and log connection into the jobs and transformations. More about that on the next slide.
- At the end of the batch run we also archive logging information. Even if you have been using different sets of logging tables, all information is merged back together, allowing historical reporting on your data integration processes. Also, the archive tables avoid that your logging tables fill up and make the kettle development interface become sluggish when visualizing the logging.

The rejects step isn't the only plug-in we have written over the last few years. The next slide illustrates some other steps that have been developed.
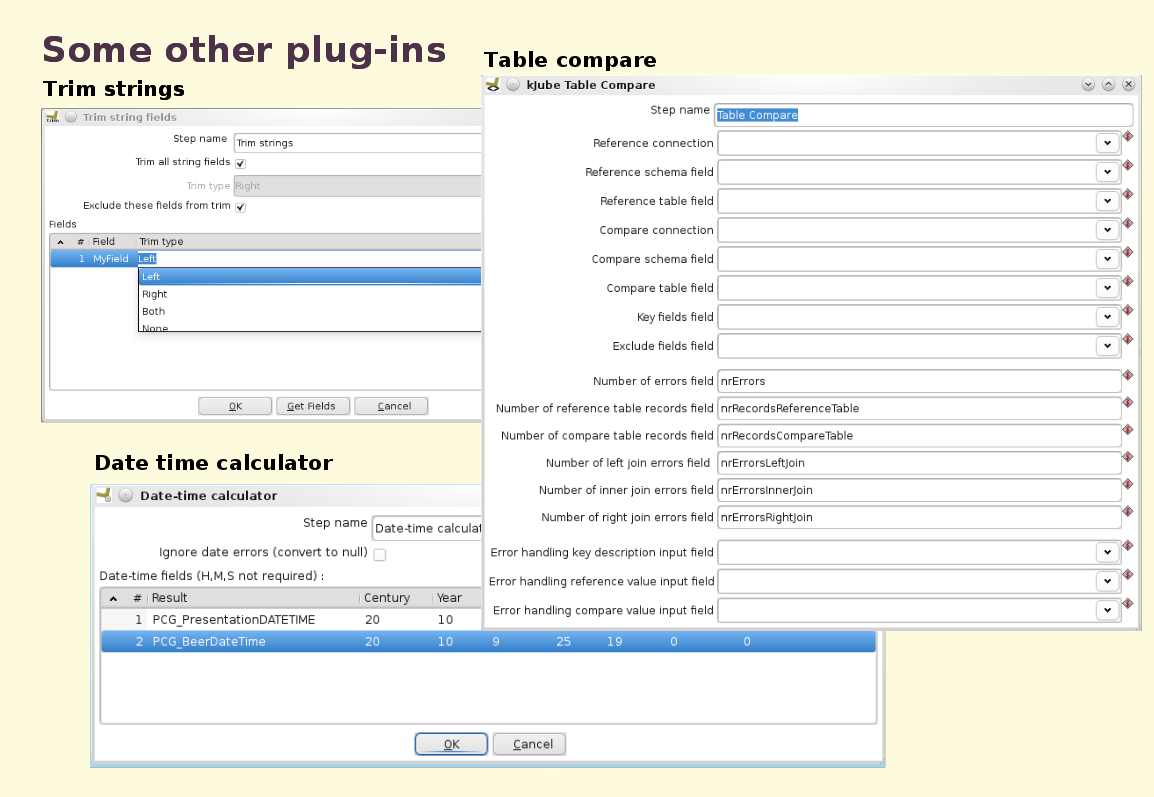
- Trim strings
- Date-time calculator
- Table compare
I have blogged about these steps before, so again, I will not write this out again. Also, one step that isn't mentioned here, but which we developed too, and has been contributed back to kettle 4.0 is the data grid step.

Another aspect of KFF are project templates. For the moment, what we have is rather meager - only the datawarehouse template is available -, but we do have quite some stuff in the pipeline that we want to deploy.
- The datawarehouse template should grow out to be a 'sample' datawarehouse project containing lots of best practices and possibly a lot of reusable dimensions (as in date dimension, time dimension, currency dimension, country dimension, ...)
- The data vault generator is a contribution from Edwin Weber which came to us through Jos van Dongen. We are still looking into how we can add it. But it seems promissing.
- The campaign manager is a mailing application, also know as norman-mailer, which we use internally at kJube. It allows you to easily read out a number of email addresses, send mails, and capture reponses from POP3.
- The db-compare template does an automatic compare of the data in a list of tables in two databases. It will log all differences between the data in the two tables. It is something we've used for UAI testing when we need to prove our customer that UAI and PRD are alligned.

- After the presentation Roland Bouman came to me with a great idea for another template. I will not reveal anything as he has his hands full with the cookbook for the time being, and we are busy with KFF. When the time is ripe, you'll hear about this template too.
So to sum it all up: KFF pretends to be a big box, with all of the below contents.

We don't expect all of this to be in there from day one. Actually the day we presented KFF at PCG10 was day 1, so have some patience and let us add what we have over the next months.
How will KFF move forward?
Well we believe the first step was releasing something to the community. We'll keep on doing that. The code for the project is fully open source (GPL) and available no Google Code. Check code.kjube.be or go to the kettle-franchising project on google code. We'll listen to your feedback and adapt where possible!

Also we'll follow these basic guidelines:
- Make KFF deployment as simple as possible. As is simple as a kettle deploy is impossible since kettle is deployed within KFF, but if you know kettle, you know what we mean.
- We also believe that some of the functionality we have built doesn't belong in KFF but rather in kettle itself. We'll push those things back to Pentaho. (We'll try to find time to discuss with the kettle architect :-) )
- If and when something should be automated/simplified in a plug-in we'll do so.
- We believe we should integrate with other project around kettle, as the cookbook.
Who's in on this?
For the moment, Matt and myself are the drives behind this "project". Older version have been in production with some of kJube's customers for years. Sometimes they contribute, sometimes they are just happy it does what it should.

We hope to welcome a lot of users and contributers over next months.
Feedback
is always welcome!

Thanks!
